Etcd in Kubernetes
本阶段学习etcd与kubernetes,简单来说kubernetes可以看作一个应用,任何一个应用都要有数据库,kubernetes也不例外,而etcd就是kubernetes的数据库。
虽然etcd作为数据库是kubernetes的核心,但是在生产环境中并不直接和etcd打交道,而是通过API来操作资源。
这篇心法将介绍,etcd是如何工作的、工作流程及原理如何,以及在kubernetes中如何用到了etcd。
1. k8s为啥要etcd?
一个Kuberbetes的集群从high level的层面来说,有三种不同类别的control-plane processes:
- Centralized controllers:比如secheduler,controller-manager以及third-party controllers,用来配置pods和其他资源。
- Node-specific processes:最重要的一个是kubelet,用于处理根据配置来创建pod。
- API server:用来协调control plane processes和nodes。

每一个node都有kubelet,相当于是一个包工头,负责创建容器、挂载卷等任务。API是内部controller来联系kubelet的中介。
关于API server,其实工作量很少。当一个用户调用API时,API server:
- (用RBAC)来决定这次API调用是否被授权。
- 可能通过改变 webhook 更改 API 调用的负载。
- 判断负载是否有效。
- 将API负载持久化,并且返回请求信息。
- 可能会通知 API 端点的订阅者对象已更改。
现在假设使用如下命令来部署三个Pod:
$ kubectl apply -f deployment.yaml之后API server就会接收到这条请求,然后验证请求合法性,接着会将该deployment的定义保存到etcd中。
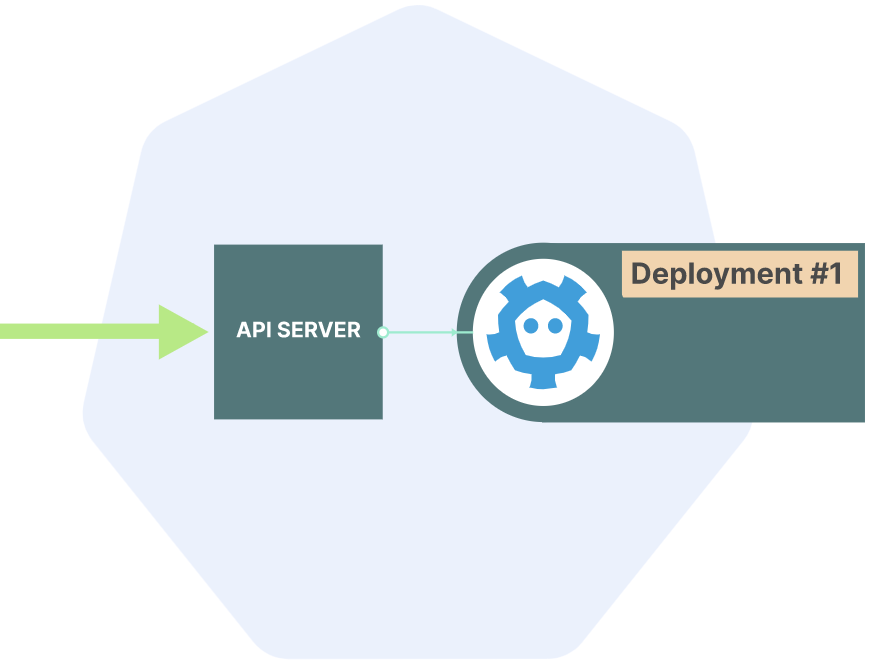
之后发生的任何事情都是由controllers以及node-specific processes来完成的,比如根据deployment决定需要运行哪些pod,每一个pod要调度运行在哪一个node上,设置networking等等。
在etcd中添加了该deployment之后,controller manager就会注意到来了新的资源。
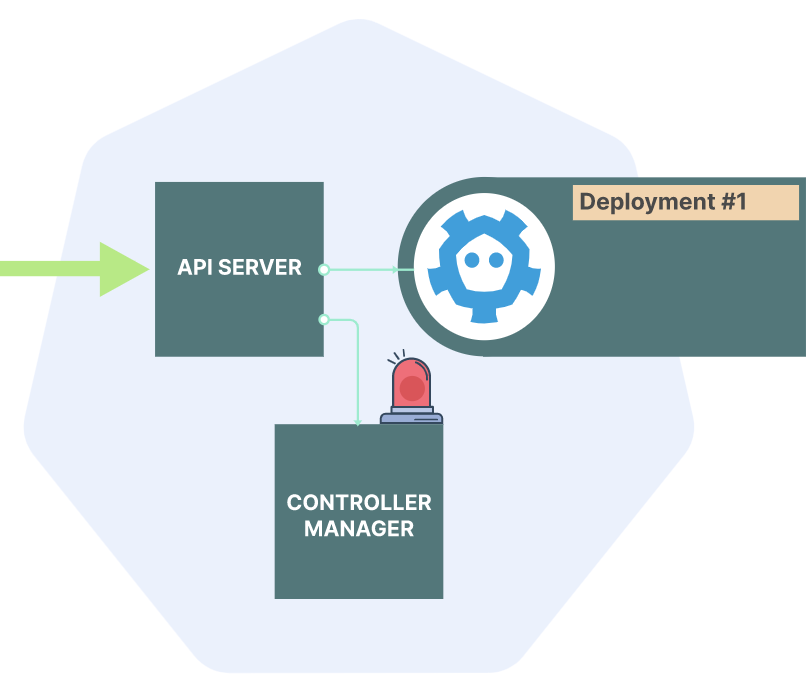
然后Deployment and ReplicaSet controllers会在etcd中保存pods的信息。
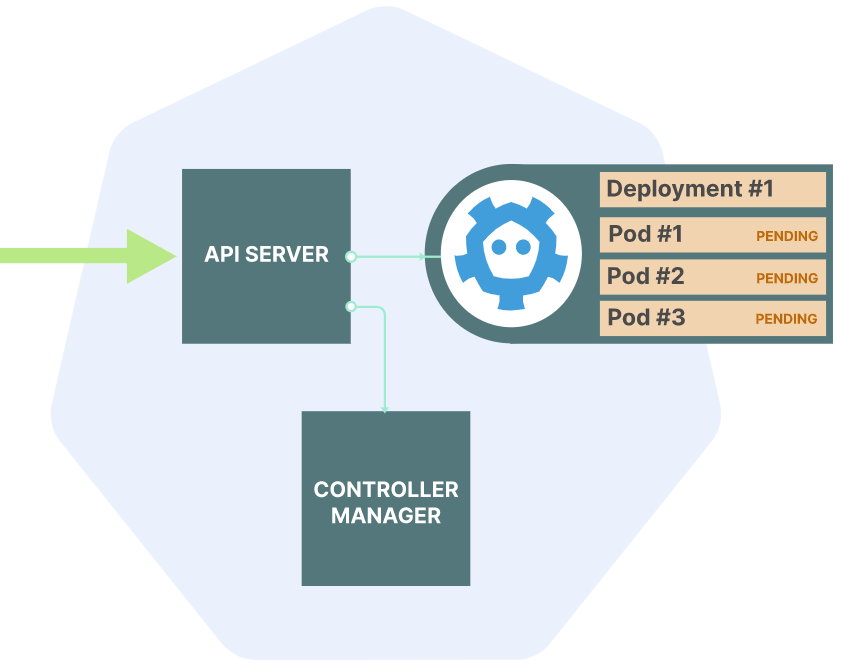
从架构上抽象地来讲,API server就是一个CRUD的应用,对于这种应用来讲,总要有个数据库的支撑,那就是etcd了。
2. 为什么选择etcd?
数据库千千万,为何kubernetes选择了etcd作为数据库?能不能用Mysql或者PostgreSQL?答案是可以的,mysql或pg并不能最好的满足k8s的需求。问题就来了,k8s需要什么样的数据库呢?
2.1 Consistency
k8s的集群是分布式的,因此API server要求数据库必须保持强一致性。
2.2 Availability
如果API server down了,那么整个k8s control plane就down了,因此数据库需要高可用。尽管不可能达到100%可用,但要尽量缩短downtime。
2.3 Consistent Performance
API server可能同一时刻会接收到大量请求,因此性能也很重要。
2.4 Change Notification
由于 API server充当许多不同类型客户端之间的集中协调器,因此当数据库发生改变时,需要notification。
2.5 Other considerations
上面是API server数据库需要的,下面这些是它不需要的:
- Large Datasets:API server只保存pods等object的metadata,因此就算是一个很大的集群,metadata加起来可能会有几百兆,多一点几个G,但绝对达不到TB的量级。
- Complex Queries: k8s的API访问模式相对固定,一般通过类型,namespace或者name来获取,因此不需要很复杂的query。
对于传统数据库来说,通常会在large datasets和complex queries上做很多优化,往往忽略了高可用和性能,而这恰恰不是k8s需要的,所以并不适合k8s。
3 Etcd到底是啥?
Etcd,是一个强一致性、分布式的key-value数据库。
- 强一致性:etcd具有严格的可串行化,这意味着一致的全局事件排序。也就是说,在一个客户端完成写之后,其余客户端读到的一定是写过之后的新值。
- 分布式:和传统数据库不一样,etcd是设计成为不同node服务的数据库,也就是说有着高可用性。
- key-value:etcd的数据模型比较简单,采用key-value存储。
除此之外,etcd一个最不一样的地方在于,k8s需要大量使用change notifications。etcd可以让客户端知道,哪一个或哪几个key发生了变化。
因为这些特性,k8s选择了etcd。当然了,不只etcd有这些特性,像Apache ZooKeeper 和 HashiCorpConsul也有着相同特性。
4 Etcd原理
etcd之所以能够保持强一致性和高可用,是因为Raft算法。Raft算法解决的问题:多个独立的进程访问同一个数据的问题。这个问题叫做distributed consensus,相应的揭发还有一种叫Paxos算法,但是比较复杂并且实现起来困难。那Raft的优点就是简单理解,实现方便。关于Raft算法的流程以及原理可以参考这里,http://thesecretlivesofdata.com/raft/ ,按照这个图理解一遍应该就没问题了。
通过上面链接中的动画演示,我们应该明白etcd集群中节点有哪些状态,节点间如何选举Leader,有了leader之后如何进行进行保持数据一致性的写操作。
简单总结一下Raft的流程:
首先应该明白在任意时刻,一个etcd集群应该有一个Leader,然后数据写操作应该是这么个流程:
- 首先客户端向etcd集群中的任一节点发送写请求。
- 如果该节点恰好是leader,那么执行该写操作,并且将此次更新同步到其他节点的日志,日志更新后,在执行真正的写操作。
- 如果该节点是follower,那么要先将该请求转发到Leader,然后参考步骤2。
- 写操作完成后,向客户端返回ACK。
如果etcd集群的leader由于某种原因掉线了,那么就要进行新一轮的选举,并且在大多数节点同意之后,才能选举成功。
etcd尽可能的保持了节点的可用,也就是说允许有节点是不可用的,那么底线在哪里?答案是看情况,大致可以参考:

通过观察可以看出,并不是说总节点数越多,可用性就越强。当节点数为3和4时,都只最多允许一个节点不可用,也就是说可用性是一样的。因此,etcd集群中节点数目通常采取奇数。
那么一个集群中应该设置多少个节点?答案还是看情况,这是一个tradeofff,可以说当节点数增加,有可能提高可用性,但是为了保持一致性,性能就会下降。一般来讲设置3个或5个。
5. Etcd使用
5.1 安装及基本使用
Etcd提供了下载脚本,https://github.com/etcd-io/etcd/releases/,只要拷贝命令放在脚本里执行就好:
ETCD_VER=v3.5.4
# choose either URL
GOOGLE_URL=https://storage.googleapis.com/etcd
GITHUB_URL=https://github.com/etcd-io/etcd/releases/download
DOWNLOAD_URL=${GOOGLE_URL}
rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
rm -rf /tmp/etcd-download-test && mkdir -p /tmp/etcd-download-test
curl -L ${DOWNLOAD_URL}/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz -o /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
tar xzvf /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz -C /tmp/etcd-download-test --strip-components=1
rm -f /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
/tmp/etcd-download-test/etcd --version
/tmp/etcd-download-test/etcdctl version
/tmp/etcd-download-test/etcdutl version装好之后其实装了三个东西:
- etcd:用于运行etcd server
- etcdctl:用于和server进行交互
- etcdutl:用于备份之类的操作
直接使用etcd命令就可以启动一个单节点的etcd集群:
$ ./etcd
...
{"level":"info","caller":"etcdserver/server.go:2027","msg":"published local member..." }
{"level":"info","caller":"embed/serve.go:98","msg":"ready to serve client requests"}
{"level":"info","caller":"etcdmain/main.go:47","msg":"notifying init daemon"}
{"level":"info","caller":"etcdmain/main.go:53","msg":"successfully notified init daemon"}
{"level":"info","caller":"embed/serve.go:140","msg":"serving client traff...","address":"127.0.0.1:2379"}观察发现可以通过127.0.0.1:2379和集群进行交互。
需要注意的是,etcd的V2和V3差别很大,因此在使用etcdctl时需要指定使用的是哪个版本。通过环境变量来指定版本:
$ export ETCDCTL_API=3接着就可以使用etcdctl来读写数据了:
$ ./etcdctl put foo bar
OK
$ ./etcdctl get foo
foo
baretdctl get会打印key和value,如果只想打印value可以加上--print-value-only。
可以加-write-out=json看到更详细的信息:
$ ./etcdctl get --write-out=json foo
{
"header": {
"cluster_id": 14841639068965180000,
"member_id": 10276657743932975000,
"revision": 2,
"raft_term": 2
},
"kvs": [
{
"key": "Zm9v",
"create_revision": 2,
"mod_revision": 2,
"version": 1,
"value": "YmFy"
}
],
"count": 1
}观察看到,打印出来的信息是base64编码的。
打印出来的信息啥意思呢?
version:1revision:2create_revision:2mod_revision:2
version 作用域为 key, 某一个 key 的修改次数(从创建到删除);
revision作用域为集群,逻辑时间戳,全局单调递增,任何 key 修改都会使其自增;
create_revision作用域为 key, 等于创建这个 key 时的 Revision, 直到删除前都保持不变
mod_revision作用域为 key, 等于修改这个 key 时的 Revision, 只要这个 key 更新都会改变。
当修改值之后,打印信息变化如下:
$ ./etcdctl put foo baz
OK
$ ./etcdctl get --write-out=json foo
{
"header": {
"cluster_id": 14841639068965180000,
"member_id": 10276657743932975000,
"revision": 3,
"raft_term": 2
},
"kvs": [
{
"key": "Zm9v",
"create_revision": 2,
"mod_revision": 3,
"version": 2,
"value": "YmF6"
}
],
"count": 1
}etcd并且支持查看旧版本数据,使用--rev参数来指定集群的版本:
$ ./etcdctl get foo --rev=2 --print-value-only
bar
$ ./etcdctl get foo --rev=3 --print-value-only
baz删除数据:
$ /etcdctl del foo
1
$ ./etcdctl get foo删除后返回的1代表删除key数量。
但是删除并不是永久的,还是可以通过--rev参数来查看旧版本数据。
$ ./etcdctl get foo --rev=3 --print-value-only
baz5.2 多值返回
etcd的一个特性就是可以一次返回多个value。
首先创建一些数据:
$ ./etcdctl put myprefix/key1 thing1
OK
$ ./etcdctl put myprefix/key2 thing2
OK
$ ./etcdctl put myprefix/key3 thing3
OK
$ ./etcdctl put myprefix/key4 thing4
OK一次访问多个值:
$ ./etcdctl get myprefix/key2 myprefix/key4
myprefix/key2
thing2
myprefix/key3
thing3可以通过--prefix来指定key的前缀:
$ ./etcdctl get --prefix myprefix/
myprefix/key1
thing1
myprefix/key2
thing2
myprefix/key3
thing3
myprefix/key4
thing45.3 监听修改
首先在一个终端输入以下命令:
$ ./etcdctl watch --prefix myprefix/然后在另一个终端修改一些数据:
$ ./etcdctl put myprefix/key1 anewthing
OK
$ ./etcdctl put myprefix/key5 thing5
OK
$ ./etcdctl del myprefix/key5
1
$ ./etcdctl put notmyprefix/key thing
OK接着在第一个终端观察变化:
PUT
myprefix/key1
anewthing
PUT
myprefix/key5
thing5
DELETE
myprefix/key5可以看到,因为监听了myprefix的数据,因此在第一个终端打印出了修改,而前缀notmyprefix并没有打印信息。
并且watch也可以加--rev参数来查看历史版本:
$ ./etcdctl watch --rev=2 foo
PUT
foo
bar
PUT
foo
baz
DELETE
foo5.4 多节点etcd集群
目前未知,集群中只有一个节点,甚至不能称之为一个集群。现在我们来启动一个三节点的集群,来看看到底是怎么高可用的。
首先为三个节点创建数据保存的文件夹:
$ mkdir -p /tmp/etcd/data{1..3}启动集群时,我们必须知道其中每一个节点的IP地址以及端口,这样节点之间才能相互通信。
对于三个节点,客户端的端口也就是客户端可以连接的端口设置为2379,3379和4379,peer端口也就是node之间通信的端口设置为2380,3380以及4380。
通过一下命令启动第一个节点:
$ ./etcd --data-dir=/tmp/etcd/data1 --name node1 \
--initial-advertise-peer-urls http://127.0.0.1:2380 \
--listen-peer-urls http://127.0.0.1:2380 \
--advertise-client-urls http://127.0.0.1:2379 \
--listen-client-urls http://127.0.0.1:2379 \
--initial-cluster node1=http://127.0.0.1:2380,node2=http://127.0.0.1:3380,node3=http://127.0.0.1:4380 \
--initial-cluster-state new \
--initial-cluster-token mytoken其中几个参数:
--name:指定了节点的名字--listen-peer-urls和--initial-advertise-peer-urls:指定节点之间的通信地址和端口--advertise-client-urls和--listen-client-urls指定客户端与节点通信的地址和端口--initial-cluster-token指定一个集群中节点公用的token--initial-cluster指定集群中所有节点,这样才能找到其他节点
同理在新的终端中启动第二个和第三个节点:
$ ./etcd --data-dir=/tmp/etcd/data2 --name node2 \
--initial-advertise-peer-urls http://127.0.0.1:3380 \
--listen-peer-urls http://127.0.0.1:3380 \
--advertise-client-urls http://127.0.0.1:3379 \
--listen-client-urls http://127.0.0.1:3379 \
--initial-cluster node1=http://127.0.0.1:2380,node2=http://127.0.0.1:3380,node3=http://127.0.0.1:4380 \
--initial-cluster-state new \
--initial-cluster-token mytoken$
bash
./etcd --data-dir=/tmp/etcd/data3 --name node3 \
--initial-advertise-peer-urls http://127.0.0.1:4380 \
--listen-peer-urls http://127.0.0.1:4380 \
--advertise-client-urls http://127.0.0.1:4379 \
--listen-client-urls http://127.0.0.1:4379 \
--initial-cluster node1=http://127.0.0.1:2380,node2=http://127.0.0.1:3380,node3=http://127.0.0.1:4380 \
--initial-cluster-state new \
--initial-cluster-token mytoken启动之后,就可以使用etcdctl加上--endpoint参数来和节点通信,这里的endpoint就是启动时--listen-client-urls指定的地址。
首先查看所有节点:
$ export ENDPOINTS=127.0.0.1:2379,127.0.0.1:3379,127.0.0.1:4379
$ ./etcdctl --endpoints=$ENDPOINTS member list --write-out=table
+------------------+---------+-------+-----------------------+-----------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+-------+-----------------------+-----------------------+------------+
| 3c969067d90d0e6c | started | node1 | http://127.0.0.1:2380 | http://127.0.0.1:2379 | false |
| 5c5501077e83a9ee | started | node3 | http://127.0.0.1:4380 | http://127.0.0.1:4379 | false |
| a2f3309a1583fba3 | started | node2 | http://127.0.0.1:3380 | http://127.0.0.1:3379 | false |
+------------------+---------+-------+-----------------------+-----------------------+------------+
读写数据:
$ ./etcdctl --endpoints=$ENDPOINTS put mykey myvalue
OK
$ ./etcdctl --endpoints=$ENDPOINTS get mykey
mykey
myvalue现在假设一个节点down了咋办?我们在第一个终端中ctrl+c,然后查看节点:
$ ./etcdctl --endpoints=$ENDPOINTS member list --write-out=table
+------------------+---------+-------+-----------------------+-----------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+-------+-----------------------+-----------------------+------------+
| 3c969067d90d0e6c | started | node1 | http://127.0.0.1:2380 | http://127.0.0.1:2379 | false |
| 5c5501077e83a9ee | started | node3 | http://127.0.0.1:4380 | http://127.0.0.1:4379 | false |
| a2f3309a1583fba3 | started | node2 | http://127.0.0.1:3380 | http://127.0.0.1:3379 | false |
+------------------+---------+-------+-----------------------+-----------------------+------------+可以看到,就算杀掉了第一个节点,还是能看到三个节点。其实meber list列出了所有节点,可以采用endpoint status产看节点状态:
$ ./etcdctl --endpoints=$ENDPOINTS endpoint status --write-out=table
{
"level": "warn",
"ts": "2021-06-23T15:43:40.378-0700",
"logger": "etcd-client",
"caller": "v3/retry_interceptor.go:62",
"msg": "retrying of unary invoker failed",
"target": "etcd-endpoints://0xc000454700/#initially=[127.0.0.1:2379;127.0.0.1:3379;127.0.0.1:4379]",
"attempt": 0,
"error": "rpc error: code = DeadlineExceeded ... connect: connection refused\""
}
Failed to get the status of endpoint 127.0.0.1:2379 (context deadline exceeded)
+----------------+------------------+-----------+------------+--------+
| ENDPOINT | ID | IS LEADER | IS LEARNER | ERRORS |
+----------------+------------------+-----------+------------+--------+
| 127.0.0.1:3379 | a2f3309a1583fba3 | true | false | |
| 127.0.0.1:4379 | 5c5501077e83a9ee | false | false | |
+----------------+------------------+-----------+------------+--------+这时,集群还在work吗?应该吧,因为大多数节点还是健康的。
$ ./etcdctl --endpoints=$ENDPOINTS get mykey
mykey
myvalue
$ ./etcdctl --endpoints=$ENDPOINTS put mykey newvalue
OK
$ ./etcdctl --endpoints=$ENDPOINTS get mykey
mykey
newvalue看起来一切正常。现在我们再重启使用第一条命令启动第一个节点的话,会发现它立马又重新加入了集群:
$ ./etcdctl --endpoints=$ENDPOINTS endpoint status --write-out=table
+----------------+------------------+-----------+------------+--------+
| ENDPOINT | ID | IS LEADER | IS LEARNER | ERRORS |
+----------------+------------------+-----------+------------+--------+
| 127.0.0.1:2379 | 3c969067d90d0e6c | false | false | |
| 127.0.0.1:3379 | a2f3309a1583fba3 | true | false | |
| 127.0.0.1:4379 | 5c5501077e83a9ee | false | false | |
+----------------+------------------+-----------+------------+--------+万一两个节点都不可用了呢?现在杀掉第一个和第二个节点,再查看状态:
$ ./etcdctl --endpoints=$ENDPOINTS endpoint status --write-out=table
{"level":"warn","ts":"2021-06-23T15:47:05.803-0700","logger":"etcd-client","caller":"v3/retry_i ...}
Failed to get the status of endpoint 127.0.0.1:2379 (context deadline exceeded)
{"level":"warn","ts":"2021-06-23T15:47:10.805-0700","logger":"etcd-client","caller":"v3/retry_i ...}
Failed to get the status of endpoint 127.0.0.1:3379 (context deadline exceeded)
+----------------+------------------+-----------+------------+-----------------------+
| ENDPOINT | ID | IS LEADER | IS LEARNER | ERRORS |
+----------------+------------------+-----------+------------+-----------------------+
| 127.0.0.1:4379 | 5c5501077e83a9ee | false | false | etcdserver: no leader |
+----------------+------------------+-----------+------------+-----------------------+可以看到报错信息是没有leader,这时尝试读写数据:
$ ./etcdctl --endpoints=$ENDPOINTS get mykey
{
"level": "warn",
"ts": "2021-06-23T15:48:31.987-0700",
"logger": "etcd-client",
"caller": "v3/retry_interceptor.go:62",
"msg": "retrying of unary invoker failed",
"target": "etcd-endpoints://0xc0001da000/#initially=[127.0.0.1:2379;127.0.0.1:3379;127.0.0.1:4379]",
"attempt": 0,
"error": "rpc error: code = Unknown desc = context deadline exceeded"
}
$ ./etcdctl --endpoints=$ENDPOINTS put mykey anewervalue
{
"level": "warn",
"ts": "2021-06-23T15:49:04.539-0700",
"logger": "etcd-client",
"caller": "v3/retry_interceptor.go:62",
"msg": "retrying of unary invoker failed",
"target": "etcd-endpoints://0xc000432a80/#initially=[127.0.0.1:2379;127.0.0.1:3379;127.0.0.1:4379]",
"attempt": 0,
"error": "rpc error: code = DeadlineExceeded desc = context deadline exceeded"
}
Error: context deadline exceeded这时如果重新启动两个节点,马上一切又恢复了正常:
$ ./etcdctl --endpoints=$ENDPOINTS endpoint status --write-out=table
+----------------+------------------+-----------+------------+--------+
| ENDPOINT | ID | IS LEADER | IS LEARNER | ERRORS |
+----------------+------------------+-----------+------------+--------+
| 127.0.0.1:2379 | 3c969067d90d0e6c | false | false | |
| 127.0.0.1:3379 | a2f3309a1583fba3 | false | false | |
| 127.0.0.1:4379 | 5c5501077e83a9ee | true | false | |
+----------------+------------------+-----------+------------+--------+
$ ./etcdctl --endpoints=$ENDPOINTS get mykey
mykey
newvalue可以看到就算有downtime,也是没有数据丢失的。
6. Etcd in k8s
现在我们了解了etcd的基本使用,那么就来看看在k8s中etcd的使用吧。
这里我们采用minikube集群,连接minikube集群并且装上etcd:
$ minikube start
$ minikube ssh
$ curl -LO https://mirrors.huaweicloud.com/etcd/v3.5.0/etcd-v3.5.0-linux-amd64.tar.gz
$ tar xzvf etcd-v3.5.0-linux-amd64.tar.gz
$ cd etcd-v3.5.0-linux-amd64之后的步骤有一点不同,minikube的部署采用TLS验证,因此每次请求都要提供TLS的证书和keys。
$ export ETCDCTL=$(cat <<EOF
sudo ETCDCTL_API=3 ./etcdctl --cacert /var/lib/minikube/certs/etcd/ca.crt
--cert /var/lib/minikube/certs/etcd/healthcheck-client.crt
--key /var/lib/minikube/certs/etcd/healthcheck-client.key
EOF
)此处使用的证书和密钥是由 minikube 在 Kubernetes 集群引导期间生成的。它们是为与 etcd 健康检查一起使用而设计的,但它们也适用于调试。
查看节点:
$ $ETCDCTL member list --write-out=table
+------------------+---------+----------+---------------------------+---------------------------+------------+
| ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER |
+------------------+---------+----------+---------------------------+---------------------------+------------+
| aec36adc501070cc | started | minikube | https://192.168.49.2:2380 | https://192.168.49.2:2379 | false |
+------------------+---------+----------+---------------------------+---------------------------+------------+可以看到,minikube只有一个etcd节点。
Kubernetes API 是如何在etcd中保存数据的呢?所有k8s的数据都有/registry前缀:
$ $ETCDCTL get --prefix /registry | wc -l
5882和pod有关的数据有着/registry/pods前缀:
$ $ETCDCTL get --prefix /registry/pods | wc -l
412一般命名格式是这样:/registry/pods/<namespace>/<pod-name>
$ $ETCDCTL get --prefix /registry/pods/kube-system/ --keys-only | grep scheduler
/registry/pods/kube-system/kube-scheduler-minikube--keys-only只打印key。
实际数据长啥样呢??
$ $ETCDCTL get /registry/pods/kube-system/kube-scheduler-minikube | head -6
/registry/pods/kube-system/kube-scheduler-minikube
k8s
v1Pod�
�
kube-scheduler-minikube�
kube-system"*$f8e4441d-fb03-4c98-b48b-61a42643763a2��نZ可以看到是一堆乱码,因为k8s API是以二进制形式保存数据的。如果像查看json形式的话,应该用API而不是直接访问etcd。
可以采用watch来监听default ns的变化:
$ $ETCDCTL watch --prefix /registry/pods/default/ --write-out=json然后在另一个终端:
$ kubectl run --namespace=default --image=nginx nginx
pod/nginx created可以看到在第一个终端:
{
"Header": {
"cluster_id": 18038207397139143000,
"member_id": 12593026477526643000,
"revision": 935,
"raft_term": 2
},
"Events": [
{
"kv": {
"key": "L3JlZ2lzdHJ5L3BvZHMvZGVmYXVsdC9uZ2lueA==",
"create_revision": 935,
"mod_revision": 935,
"version": 1,
"value": "azh...ACIA"
}
}
],
"CompactRevision": 0,
"Canceled": false,
"Created": false
}再次说明,在生产环境中并不会直接和etcd打交道,而是通过API来访问。可以预想的是,API底部也是通过etcd来读写数据的。
7.替换etcd
在k8s中使用了etcd,但是在某些场合下比如测试环境或者嵌入式环境,我们想要轻量级,那etcd就不合适了。那么,就可以使用k3s,并且使用你想使用的数据库。



