20. Paging: Smaller Tables
- 继续之前的问题,page table可能过大,上一节采用了TLB缓存的方法,这一节来看看不同的方法。问题来了,如何让page table 变小呢?有哪些方法?这些方法又会带来哪些问题?
20.1 Simple Solution: Bigger Pages
- 如题,当使用更大的page时,那么page数就会变少,自然page table就会变小。
假设地址空间32位,page大小4KB,page-table entry大小4B,那么page table大小就是。
现在将page大小变为16KB,那么page table大小就是 。可以看到page table大小变为原来的四分之一。
但是这种方法同样存在着问题,page越大,那么page内出现内部碎片的可能性就越大。因此大部分系统使用的还是相对较小的page,比如4KB (as in x86) or 8KB (as in SPARCv9)。
20.2 Hybrid Approach: Paging and Segments
- 平衡之道,采用将paging和segmentation相结合的方法来减小page table的大小。
举个栗子,地址空间16KB,page1KB,因此共有16个page,page和page frame的映射关系如下:
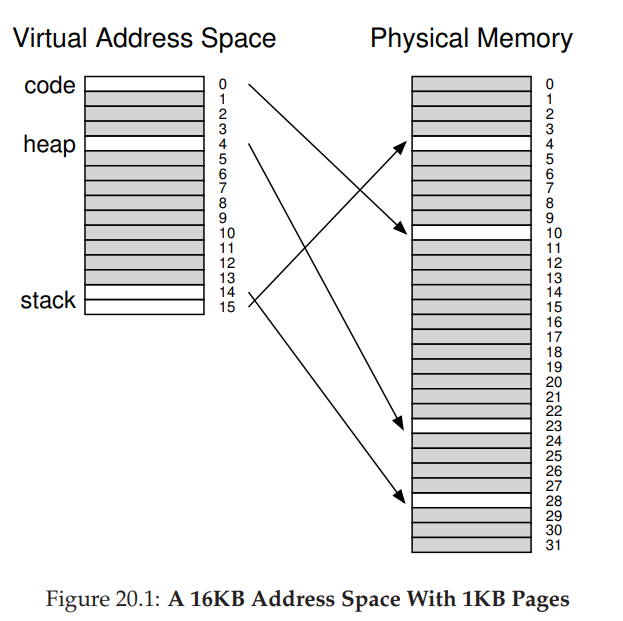

从上图可以看到,虽然大量的page没有使用,但是依旧保存在page table中(将valid位设为0)。也就是说page table中其实保存了大量无用信息,假如地址空间再大一点,可以想象保存的无用信息可能会更多。所以为什么不采用segmentation的思想只保存valid的信息呢?
我们的平衡之道是:与其给每个进程设置一张page table保存所有page映射关系,不如给每个地址空间的segment设置一张page table。segmentation可以保存变长的信息,因此可以使用segmentation的方法保存变长的page table,这就是我们将segmentation和paging结合的平衡之道。
在这个栗子里,我们将设置三张page table,因为有三个逻辑segment:code、stack、heap。回忆一下segmentation方法,给每个进程的逻辑segment设置一对base and bound寄存器,其中base寄存器保存地址空间在物理内存的起始位置,bound保存了地址空间的边界。那么在我们的平衡之道中仍将采用base and bound的方法,只不过,这里的base保存的是每个page table在物理内存中的起始地址,bound保存的是page table的边界(也就是其中保存了多少个valid的page)。
假设32位地址空间,page大小4KB,地址空间被分为四个segment。使用其中的三个segment:code、heap、stack。对于32位地址,使用最高两位来判断当前地址指向的是哪个segment,00代表未使用,01代表code,10代表heap,11代表stack。

当TLB miss的时候,硬件使用segment bit(SN)来决定使用哪一对base and bound寄存器;然后通过VPN去base指向的page table中寻找对应PTE:

注意,bound寄存器中保存的是当前segment中有效的page值。假设,code segemnt只使用了前三个page,那么对用的page table会有三个PTE对应保存VPN0、1、2。无效的信息没有保存,因此page table的大小就减小了。
当然了,这种做饭并非完美。第一,还是要使用segmentation的思想,就像之前提到的,这种思想不够灵活,因为它定好了地址空间的使用模式;第二,segmentation总是会导致外部碎片。因此我们还需要更好的方式来解决page table过大的问题。
20.3 Multi-level Page Tables
- 重量级方法来了,multi-level page table,多级页表,还是那句话,在计算机里,没有什么是加一层解决不了的,如果有,就再加一层。用一句话概括多级页表就是,保存page table的page table,即套娃。
本来想细节解释一番如何做成多级页表,但是文字功底有限,不如直接看图,一图胜千言。
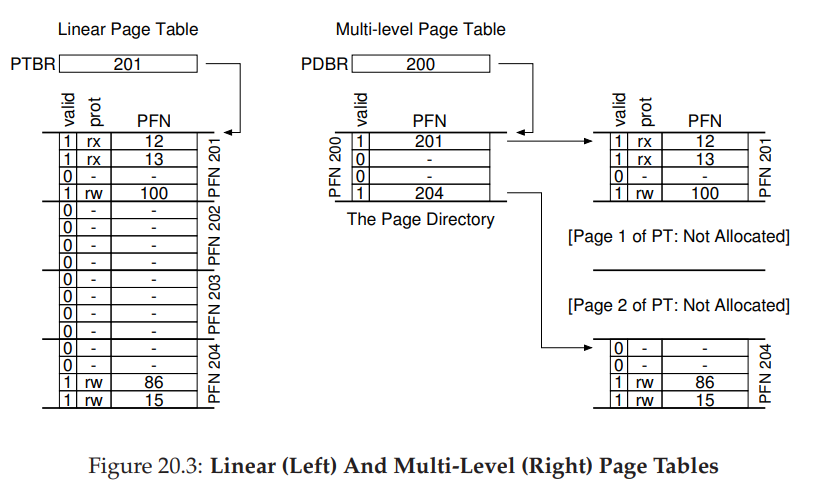
简单解释一下吧。
可以看到,最左边就是我们原本的page table,中间是我们采用的新的数据结构page directory(本质上和page table是类似的,也就是page table的page table)。
如果仅仅使用page table不使用多级页表,那么就需要将左边的整个page table都保存在内存中。而在多级页表中,将page table分成若干个unit,每个unit是一个page的大小;既然将整个page table分成这么多unit了,也就意味着我们不需要把原本的page table连续的存放在内存中了,理论上我们可以将每一个uint放在内存的不同位置。既然都分开放了,那么page table中那些空的位置就不用实际上放在内存中了呀,可以只将使用过的那些位置保存在内存中。
那么问题就来了,对于原本连续存放在内存中的page table,我们只需要一个page table 寄存器就可以知道它的起始位置;但是当这个page table分散地存在内存中,我们如何知道他们保存在什么位置呢?
ok,终于来到了page directory。上面那个问题的答案就是page directory,其中保存了page table的每个unit实际保存在内存的什么位置。有了page dir,对于上图而言,可以看到原本的page table被分成了四个unit,但是实际上只有一头一尾两个unit是保存在内存中的,中间的并没有保存,从而达到节省空间的目的。
page directory中每个元素叫做page directory entry(PDE),其中包含了valid和PFN,valid表示是当前PDE对应的page是否有效,PFN代表了对应的page的物理块号。
综上所述,多级页表只不过是套娃而已,本来page table就是把地址空间分成page,将每个page离散地存在内存中;现在又把page table分成page,再离散地存在内存中,仅此而已。
- 说了这么多,来举个栗子吧:
地址空间16KB,page大小64B,因此虚拟地址14位,其中8位VPN,6位offset。如下图,白色代表使用了,灰色代表没有使用:

那么对于page table,一共有个entry,整个page table大小位。
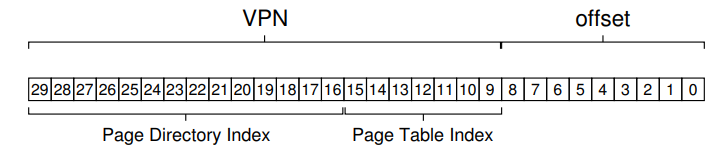
现在来看看多级页表怎么个情况。由于每个page是64B,那么可以将page table分成个page,每个page中保存了16个()个PTE。在page dir中,每page dir entry对应page table中的一个unit(也就是一个page 大小的 PTE),也就是page dir中有16个PDE。因此对于一个虚拟地址,我们需要用VPN的最高四位来代表在page dir中的index:
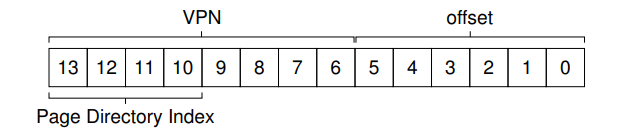
一旦我们得到了page dir index,就可以计算出对应PDE的物理地址:
PDEAddr = PageDirBase + (PDIndex * sizeof(PDE))
有了PDE地址,就可以访问其中的内容,也就是保存的page table中的page的物理地址。如果ODE标记为无效,那么访问就是无效的会抛出异常。如果是有效的,那么我们就需要再从虚拟地址中VPN的剩下位中得到在page table中的某个page的page table entry的下标:

有了page table entry的下标就可以计算出对应的物理地址:
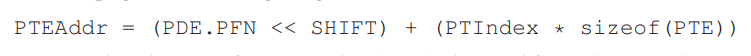
那么就可以访问对应PTE中的内容,也就是记录的地址空间中的page对应的物理块号PFN,于是就可以将虚拟地址翻译为物理地址了,至此目的应该就达成了。
- 什么?还是觉得抽象?来看个实际的栗子吧:
对于上述栗子,page dir的图长这样:
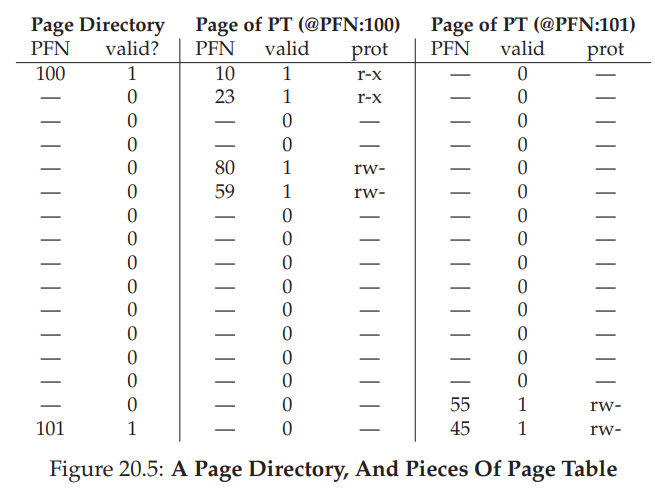
实际上,没有多级页表时,我们需要把整个page table保存在内存中,但是有了多级页表,就只要保存page table中的两个page大小的PTE,再加上page dir(一个page大小),总共加起来只需要三个page的内存。
考虑这个虚拟 VPN 254 :11 1111 1000 0000。用前四位来表示page dir 的index,也就是1111 ,十进制就是15,page dir的最后一个entry:
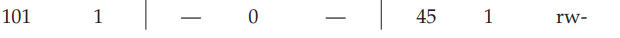
根据这里保存的信息,我们就找到了对应page table的page的PFN:101。
接着我们用后面的四位 1110来得到page table中的page里面的index,也就是十进制14(倒数第二个),也就是地址空间的下标254的page table entry:
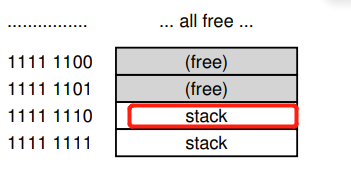
假设这个entry中保存的PFN为55,这样就计算出page实际的物理地址:
PhysAddr = (PTE.PFN << SHIFT) + offset = 00 1101 1100 0000 = 0x0DC0。
- 虽然实际上流程不是很复杂,但是说起来真的好麻烦(不想再来一遍了)。
- wc,等等怎么还有超过两级的多级页表???不想再说了,其实实际原理都是一样的,只不过又加了一层,需要多翻译一次而已:
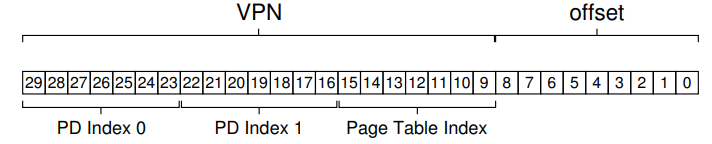

实际上超过两级的页表还是很有必要的,因为有可能page dir过大保存在内存中还是很占内存,所以需要对page dir在分页,也就是大于两级的多级页表。
- 可能还有一些更节省空间的方法,比如 Inverted Page Tables 或 Swapping the Page Tables to Disk,目前看不动了。所以,summary:
20.6 Summary
- 我们的目的就是节省内存空间,因此要想方法把page table变小,于是就有了多级页表,也就是page table的page table。



