19. Paging: Faster Translations (TLBs)
- Page table存在内存中,因此使用paging的方法需要额外的内存访问,因此比较耗时。问题:如何加速地址翻译并且避免额外的内存访问?需要哪些硬件支持?OS又需要做什么?
- 方法叫translation-lookaside buffer或者TLB,是MMU的一个部分。其实就是对于经常访问的page frame的一个缓存,因此也叫做address-translation cache。每次进行地址翻译时,先去TLB中找,如果没有再去内存中找。
19.1 TLB Basic Algorithm

- 考虑一个简单的linear page table,一个由硬件管理的TLB。
想通过VPN来找到FPN的时候,先去TLB中找,如果找到称为 TLB hit,就可以从TLB中取得FPN。
如果在TLB中没有找到就称TLB miss,这种情况下就和之前一样去内存中找到对应的PTE,从PTEAddr中拿到PTE,再从PTE中拿到PFN,并且更新TLB。
最后重新执行该指令就会hit了。
19.2 Example: Accessing An Array
- 举个栗子,一个整数数组,有10个4字节的整数,虚拟地址是100开始;地址空间8位,也就是256B,每个 page 16B,也就是说一共有16个page,因此4位VPN,4位offset。

考虑这段C代码:

简单起见,我们只考虑循环的内存访问。
当访问第一个元素a[0]时,虚拟地址100,VPN06,因为是第一次访问,所以 TLB中VPN06对应的FPN肯定是空,TLB miss。当访问第二个元素a[1]时,神奇的事情发生了,TLB hit!为什么呢?因为对于第一个元素,TLB miss之后会去内存中找到VPN06对应的FPN放到TLB中,而第二个元素和第一个元素都是属于VPN06的,因此第二次TLB hit!同理a[2]也是TLB hit!
同理可得,a[3] miss,a[4] hit,a[5] hit,a[6] hit;a[7] miss,a[8] hit,a[9] hit;可以计算出hit比例是70%。我们通过 spatial locality减少了内存访问。如果地址空间再大一点的话,比如4KB,那么整个数组就可以放在同一个page中,那么就只会在第一次miss,其他都是hit。
注意,当我们在该程序中再次访问该数组时,会100%hit,这利用了temporal locality。
19.3 Who Handles The TLB Miss?
- 谁来处理TLB miss?答案有两个:硬件或者OS。
早期,硬件有着complex instruction sets (CISC,complex-instruction set computers),因此由硬件来处miss。硬件通过page table register记住page table的位置,当miss时,从page table中找到PTE再找到PFN。
现代系统一般使用RISC(reduced-instruction set computers),由软件管理TLB,也就是OS。当miss时,OS raises an exception,切换到kernel mode然后jump 到 trap handler,对应的handler里有处理miss的代码,运行这段代码,就会从page table中找到对应地址,使用特权指令更新TLB,然后return from trap ,之后硬件再retry 指令。
- 现在我们再来看亿点点细节:
第一,这里的return from trap和普通的return from trap指令不太一样。普通的return from trap指令return后是到陷入trap的后面的代码,继续往下执行;而处理TLB miss的return from trap指令return后是return到这条指令开头,需要retry这条指令。
第二,在运行TLB miss handler代码时,在这段代码内要避免造成TLB miss,不然就会一直循环TLB miss。
- 软件管理TLB的一个好处就是比较灵活,可以使用任意数据结构来实现page table;另一个好处就是简单。
19.4 TLB Contents: What’s In There?
- 典型的TLB可能包含32、64或128个元素。每个元素长这样:
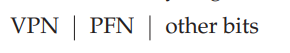
可以看到和PTE很像,但是other bits又有所不同。
valid bit:表明这个元素的是否有效。
protection bit:表明这个page能被怎样访问。比如读写、读执行等。
等等
19.5 TLB Issue: Context Switches
- 注意,可能多个进程的PN to PFN信息同时存储在TLB中,对这种情况如何控制?
举个栗子,进程P1正在运行,TLB中保存了P1的VPN10 to PFN 100。进程P2退出了,但是一会可能要切换到P2,TLB中保存了P2的VPN10 toPFN 170:
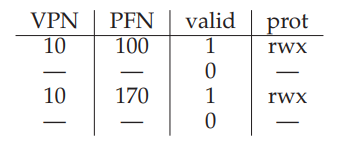
问题来了,当context switch的时候,如何保证TLB中上一个进程的信息对于即将要运行的进程来讲是无效的呢?硬件和OS又需要做什么来达到上述目的呢?
- 有很多种做法
一种做法是当context switch的时候就刷新TLB,因此对于下一个进程来讲TLB是空的。可以简单的把valid设置为0。但是这种做法在频繁切换进程时性能较差。
为了解决上述问题,可以通过硬件的支持来让不同的进程之间共享TLB。可以在TLB中加上ASID(address space identifier)字段用于表明当前这个翻译是给哪个进程用的,举个栗子:

这样在context switch的时候就不需要清空TLB了。当然存在两个进程共享page frame的情况:

19.6 Issue: Replacement Policy
- 对于所有缓存来说,都存在一个共性问题:cache replacement。当缓存满了的时候,如何选择一个来替换?问题来了:在TLB满了的时候,如何选择一个entry来替换?当然目标是尽可能减少miss rate。
- 最常见的做法是least-recently-used LRU,还有random,各有优劣。
19.7 A Real TLB Entry
- MIPS R4000的TLB entry如图

32位地址空间,每个page4KB,因此VPN20位,12位offset。但是在图中VPN只有19位,用户的地址空间最多用到一半?(好像是这个意思,原文:user addresses will only come from half the address space (the rest reserved for the kernel))。物理内存64GB,因此PFN24位。
global bit(G):表明该page对于进程是否全局共享,如果是那么就忽略ASID位。
ASID:8位,用于区分不同进程。
Coherence:3位,用于表明硬件是通过何种方式缓存一个page的。
dirty:表明page是否被修改过。
还有一些没有用到。
19.8 Summary
- TLB用于缓存page table记录的翻译。
- 但还是存在问题,比如短时间内大量进程切换,导致TLB中缓存的page不够了,那么还是会有很多的TLB miss,超过了TLB coverage,下一章讨论解决方法。



